안녕하세요~ 서버 개발자 최승환입니다~ 👋
이 글은 팀의 레거시 인프라 환경을 개선 했던 경험을 공유하기 위해 작성하게 되었습니다.
으레 스타트업이란 신규 개발과 기술부채 해결 사이에서 항상 고민하게 되는 것 같습니다. 저희 팀도 마찬가지로 그간 해결하지 못했던 레거시가 많이 쌓여 있었습니다.
인프라 개선 업무는 제가 입사한 후 2개월 정도 된 시점부터 기술 조사와 작업을 진행하게 되었습니다. 이전엔 비교적 인프라가 잘 구축되어 있는 팀에 속해 있기도 하고, 포지션도 달라 인프라 관련 업무를 할 일이 없었지만, 입사 후 살펴본 저희 팀의 인프라 환경을 살펴 본 후, 안정성과 개발 생산성 향상을 위해, 프로젝트와 인프라 환경 개선 업무를 진행하기로 CTO 팀과 논의 후 결정하게 되었습니다.
이번 작업이 팀 기여와, 제 개발 스킬 향상에 많은 도움이 되었던 것 같습니다. 모쪼록 제 경험담이 다른 분에게도 도움이 되었으면 좋겠습니다. 🙇♂️
기존 환경은 어떠하였고, 어떤 의사 결정 과정들을 거치게 되었는가?
기존 Node.js 서버는 웹 Client와 API 서버가 하나의 프로젝트로 통합되어 있었습니다. 그리고 Node.js LTS가 18 버전이 나온 시점에서, 서버 프로젝트는 Node 10 버전을 사용하고 있었고, 또한 프로젝트 내의 주요 로직들이 7년 이상 된 레거시 코드로 동작하는만큼, 함께 사용하는 라이브러리들도 이미 deprecated 된 것도 있는 등, 레거시가 굉장히 심한 상황이었습니다. (현재는 NestJS로 신규 백엔드 서버를 구축한 상태입니다.)
이에 대한 개선을 위해 먼저 웹 Client와 API 서버를 서로 다른 프로젝트로 분리 하고자 했습니다. 웹 Client 보다 API 서버가 상대적으로 많은 리소스를 사용하므로, 트래픽에 따라 서버 인스턴스를 확장할 때, 웹 Client에 불필요한 리소스가 할당되는 문제가 있었습니다. 또한, 웹 Client는 Angular를 사용하고 있어, React를 주로 사용하는 현재의 개발 시장과 기술 스택이 맞지 않았습니다. (개발자 수급 문제)
또한, 레거시 코드가 심각하게 남아 있는 API 서버를 새로운 백엔드 서버로 재구축 하려 해도, 웹 Client와의 결합성으로 인해, 두 애플리케이션의 연결을 끊어야만 했습니다.
더욱이, Node 10 버전의 레거시와 deprecated 된 모듈들을 리팩토링 하기 위해, Node.js 버전을 업그레이드 하려 해도, 구버전의 Ubuntu OS와 Node.js 버전 간의 호환성 문제, 서버 인스턴스에서 동작 중인 다른 Node 애플리케이션과의 버전 이슈 등 여러 요인들이 프로젝트에 영향을 미치던 상황이었습니다.
이러한 상황에서 각 애플리케이션의 환경을 독립적으로 제공 할 필요성을 느끼게 되었습니다. 이로써 컨테이너 기술을 도입하게 되었고, 컨테이너 관리를 위해 컨테이너 오케스트레이션 도구인 Kubernetes 를 도입하게 되었습니다.
인프라 환경 또한 KT 클라우드에서 AWS 클라우드로 이전하기로 결정 하였습니다. Kubernetes 를 도입하기로 결정한 상황에서 EKS 라는 좋은 서비스를 제공하고 있었고, AWS 는 강력한 신뢰성과 안정성을 제공하고 있었기에, 인프라 이전 또한 반드시 해야 하는 과업이었습니다.
또한 컨테이너들의 매트릭 정보와, 로그를 수집하기 위한 모니터링 도구인, Grafana와 Loki 도 도입하게 되었습니다. 기존엔 서버 이슈가 발생할 경우, 각각의 서버 인스턴스에 쉘 접속을 통해 log 폴더에서 vim 과 같은 텍스트 에디터로 일일이 로그를 확인해 봐야 했던 반면, Loki 로 수집되는 로그를 쿼리를 활용하여 분석할 수 있게 되었습니다.
인프라 환경을 개선, 재구축 했던 일련의 과정들은 위와 같습니다.
그럼 이제 본격적으로 서버 프로젝트를 도커라이징 했던 경험부터 차근차근 서술해 보겠습니다.
독립적인 환경 제공을 위한 Docker 도입

기존의 하나의 서버 인스턴스에 여러 애플리케이션들이 구동되고 있는 방식은, 여러 애플리케이션을 하나의 운영 체제 환경에서 실행함으로써 각각의 독립된 환경이 보장되고 있지 않았습니다.
Docker를 도입한 가장 큰 이유는 각 애플리케이션에 독립적인 환경을 제공하기 위함이었습니다. 이전에는 여러 애플리케이션이 하나의 서버 인스턴스에서 실행되면서, 각 애플리케이션 간에 결합성이 있었습니다.
또한 Docker는 애플리케이션 패키징과 배포에 큰 편의성을 제공합니다. 각 애플리케이션은 독립된 컨테이너로 패키징되며, 개발 환경과 운영 환경을 동일하게 구성할 수 있게 됩니다. 이로써 환경 차이로 인한 버그와 운영상의 이슈를 사전에 방지할 수 있게 됩니다.
가상화와컨테이너비교
가상화는 하나의 물리적 서버에서 다수의 독립적인 가상 머신을 실행하여 각 가상 머신이 독립된 운영 체제를 가지고 있는 것처럼 동작하게 하는 기술입니다.
가상화는하이퍼바이저를 사용하여 여러 개의 가상 머신을 관리하고 각 가상 머신에 운영 체제를 설치합니다.
하이퍼바이저는 (하이퍼바이저 설명 문서)type1과type2라는 두 가지 주요 유형으로 구분 됩니다.Type1(베어메탈 하이퍼바이저) 은 시스템 펌웨어에 내장되어, 하드웨어 상에서 직접 실행되며, 하드웨어의 리소스를 직접 관리합니다. 그 하드웨어 위에 가상 머신이 동작하는 방식이며, 일반적으로 클라우드 환경에서는 Type1 하이퍼바이저가 사용됩니다.Type2(호스트형) 는 운영체제 상에서 실행되며, 호스트 운영체제 위에 게스트 운영체제가 동작하는 방식입니다. 대표적으로 virtualBox, VMware 등이 있습니다.
컨테이너는 애플리케이션과 해당 애플리케이션을 실행하는 데 필요한 의존 파일과 구성을 패키징한 단위로, 호스트 시스템의 운영 체제 커널을 공유하면서 각 컨테이너는 독립적인 파일 시스템과 프로세스 공간을 가집니다.
컨테이너는컨테이너 런타임을 이용하여 컨테이너를 관리합니다. 대표적인컨테이너 런타임에는Docker가 있습니다.컨테이너 런타임은 컨테이너화 된 애플리케이션을 실행하고 관리하는 도구로, 컨테이너의 생명 주기, 리소스와 스토리지, 네트워크 등을 관리하며 호스트 운영 체제와 컨테이너 간의 동작 환경을 관리해 줍니다.
서버 프로젝트 도커라이징

우선 기존 프로젝트 환경을 파악하기 위해, 기존 구성 등을 살펴 보았습니다. 다음은 서버 프로젝트를 실행하는 shell 커맨드 입니다.
## server.sh
## ... (생략)
pm2 start main.js -i <num> --name=<name>-server-0 -- --server --port <port>
pm2-runtime start main.js --name=<name>-schedulers -- --schedulers
## ...보다시피, 서버 프로젝트는 같은 코드를 공유하는 API 서버와 스케줄러 이 두 가지 유형이, 실행 시 전달 받는 argument에 (—schedulers , —server) 따라 구분되어 실행되고 있었습니다. 따라서 이 두 유형으로 구분하여 컨테이너화 작업을 진행 하였습니다.
# dockerfile
# builder stage
FROM --platform=linux/amd64 node:10.24.1 AS builder
# ARG, ENV...
# ... 필요 패키지 다운로드
RUN npm install
# server stage
FROM --platform=linux/amd64 node:10.24.1 AS server
COPY --from=builder /server /server
# ... COPY 설정 파일들
CMD ["node", "server.js", "--server", ...]Docker 이미지 빌드 절차는, 프로젝트 빌드에 필요한 동작을 수행하는 builder 스테이지와, 서버 실행에 필요한 것들만 copy 해 사용하는 server 스테이지로 나누어 빌드하는, 멀티 스테이징 기법을 사용하였습니다.
멀티 스테이징 기법을 사용하지 않고, 프로젝트를 도커라이징 하였을 때, 빌드 된 이미지 사이즈가 1.5GB 정도 되었기에 반드시 최적화가 필요 했습니다.
멀티 스테이징 기법이란 Docker 이미지 빌드 시에 여러 스테이지를 사용하여 이미지 크기를 최적화 하고, 이미지에 불필요한 파일들을 제거하는 데 도움을 주는 기술입니다.
이렇게 최적화 된 이미지 당연, CI/CD 파이프라인에서 빌드 시간이 단축되는 성능 향상 효과도 있습니다. 이미지 파일이 업로드 되는 레지스트리의 공간 또한 절약할 수 있습니다.
builder 스테이지 에서는 프로젝트 빌드에 필요한 개발 도구, 의존성 등을 받아 프로젝트 빌드 동작을 수행하고, server 스테이지에서 빌드한 결과물과 실행에 필요한 몇가지 파일만 가져와 이미지 용량을 최적화 할 수 있었습니다. 또한 이미지 관리를 위해 AWS ECR 을 사용하였는데, CI/CD 파이프라인을 거쳐, 버전별로 업데이트 되는 이미지의 용량을 최적화 해, 레지스트리 공간을 절약할 수 있었습니다.
(시행 착오) 문제 해결을 위해 Node.js 더 깊게 파보기…
도커라이징을 하면서 여러 시행착오를 겪었지만, 그 중 사전에 알고 있었더라면 가장 손쉽게 해결할 수 있었던 것이 —-platform 키워드 입니다.
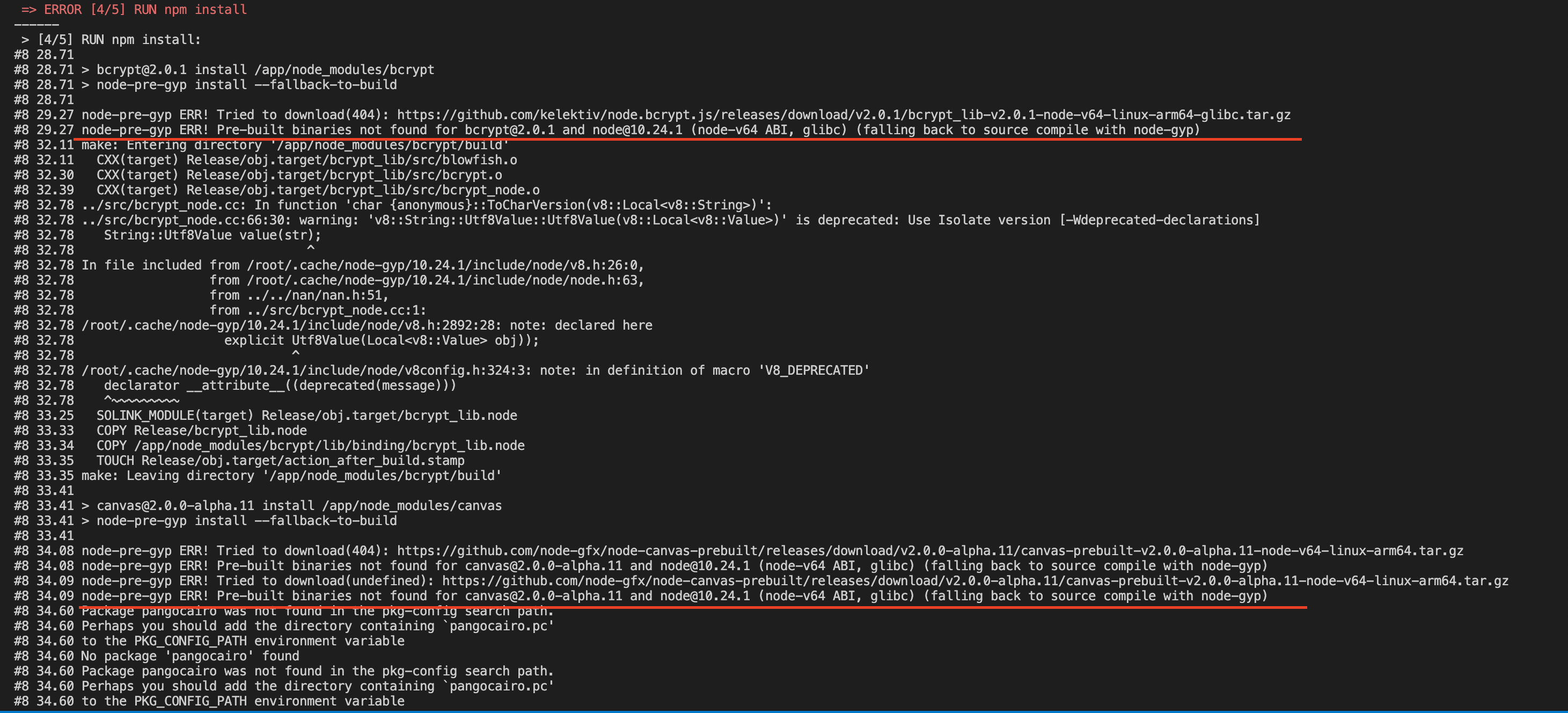
위 스크린샷을 보면, 프로젝트 의존성 모듈을 설치하는 중에, bcrypt와 canvas 모듈에서 node-pre-gyp 과 관련된 에러가 났음을 알 수 있습니다. 일단 오류를 발견한 저는 문제를 해결하기 위해 계속해서 깊게 파고 들어갔습니다… 🤦♂️
일반적으로 javascript로 작성된 모듈의 경우엔 해당 파일들을 받아와 require 또는 import 하여 사용하게 되지만, V8 엔진과의 연동을 위한 목적으로 C/C++ 로 제작된 네이티브 모듈들은, node-gyp 을 이용하여 빌드하게 됩니다.
node-gyp 이란 Node.js 에 포함된 gyp 라는 빌드 도구를 기반으로 하는 크로스 플랫폼 CLI 도구입니다.
일반적으로 네이티브 모듈은 CPU 집약적이거나 성능이 중요한 기능을 작업할 때 사용됩니다. Javascript 보다 연산 속도가 빠른 C++로 작업하며 이미 C++로 작성된 라이브러리를 가져다 사용하거나, Javascript의 가비지 컬렉션 보다 더욱 직접적인 메모리 할당/해제로 최적화 작업을 하기 위해 네이티브 모듈을 사용합니다. 프로젝트에서 성능이 중요한 로직만 네이티브 모듈로 따로 구현하여 최적화 하는 기법도 있습니다.
네이티브 모듈을 설치하려고 할 때, 해당 모듈은 보통 binding.gyp 라는 파일을 포함하고 있습니다. 이 파일은 빌드 구성을 정의하며 모듈 설치 단계에서 C++ 코드를 컴파일 하는 데 사용됩니다.
node-gyp 으로 빌드하려면, 시스템에 C++ 컴파일러가 설치 되어 있어야 합니다. 이전 회사에서도 프로젝트 개발 환경을 구축하기 위해 windows 환경에서는 Windows Build Tools 와 같은 프로그램을 설치해야 했습니다. 이 프로그램에 빌드 도구가 포함되어 있기 때문입니다.
물론, 매번 모듈을 설치할 때마다 C++ 코드를 빌드하는 것은 굉장히 시간 소요가 많이 들어가는 일이므로, node-pre-gyp 으로 미리 빌드된 바이너리 버전을 다운로드하여 사용하게 됩니다.
node-pre-gyp 은 모듈 제작자들이 사전에 AWS S3와 같은 곳에 호스팅 해놓은 바이너리 파일을 다운 받아 사용할 수 있게 해주는 도구입니다. package.json 에 “binary” 라는 속성에 해당 정보가 정의되어 있습니다.
NPM Script 문서를 확인해 보면, package.json 에서 수명 주기에 따른 script 동작을 정의할 수 있습니다.
{
"scripts" : {
"postinstall": "scripts/pre-install.js",
"install" : "scripts/install.js",
"postinstall" : "scripts/install.js",
"uninstall" : "scripts/uninstall.js"
...
}
}그럼, 서버 프로젝트에서 사용하고 있는 canvas 모듈의 package.json 을 살펴보겠습니다.
{
"scripts": {
"install": "node-pre-gyp install --fallback-to-build",
...
},
}install 시에 node-pre-gyp 을 이용하여 미리 컴파일 된 파일을 받아오도록 하고 있으며, —-fallback-to-build 옵션으로, 사전에 호스팅 된 파일이 없다면 직접 컴파일 하도록 되어 있습니다.
자, 여기까지 오니 이제 무엇이 문제였던 것인지 알 수 있었습니다.
제 개발 환경은 Mac M1으로, 이는 ARM 아키텍처를 기반으로 합니다. 저희 서버 프로젝트에서는 Node 10 버전을 사용하고 있었습니다. 이 구버전의 Node 에는 패키지 제작자들이 따로 ARM용 바이너리 파일을 제공하고 있지 않아, node-pre-gyp 으로 해당 바이너리 파일을 찾을 때 404 에러가 나고 있던 것이었습니다. 또한 Node 10 alpine 환경에서는 이러한 네이티브 모듈을 컴파일 하기 위한 도구들이 누락되어 있어, 도커라이징 시, 패키지 설치 과정에서 오류가 난 것이었습니다.
Docker는 빌드 시, 따로 아키텍처에 대한 정보를 명시하지 않으면, Docker Hub 혹은 다른 컨테이너 레지스트리에서 호스트 아키텍처에 따른 이미지를 가져오게 됩니다.
이는 간단하게 —-platform 키워드를 이용하여 해결할 수 있었습니다.
FROM --platform=linux/amd64 node:10.24.1 AS builder—-platform 키워드는 Docker 빌드 시, 이미지가 빌드 되는 플랫폼을 명시적으로 지정하는 옵션입니다. 위 명령어에서는 AMD64 아키텍처 기반으로 빌드할 것을 지정하였고, 서버 프로젝트의 기존 개발 환경을 유지하여 외부 라이브러리 빌드 시 발생하던 에러를 방지할 수 있었습니다.
다음으로, 조금 더 업무 효율성을 높이기 위해, Docker 를 좀 더 깊이 공부해 보기로 하였습니다.
Docker 기술을 뒷받침 하는 기반 기술들
Docker 는 개발과 배포를 혁신적으로 개선할 수 있는 컨테이너 기술을 제공합니다. 컨테이너 기술은 애플리케이션을 격리된 환경에서 실행하는 데 사용되며, 애플리케이션의 확장성과 이식성에 큰 도움을 주어 서버의 확장과 이전에 탁월합니다.
이러한 Docker 는 여러 컴퓨터공학적인 기술 요소가 함께 작동하여 이 기술을 구성하게 됩니다. 그럼, Docker 기술을 뒷받침하는 핵심 기반 기술들에 대해 알아보도록 하겠습니다.
리눅스 네임스페이스 (Linux Namespaces)
Docker는 리눅스 커널 위에서 동작합니다. 리눅스 커널은 운영체제의 핵심 부분으로, 하드웨어 자원 관리, 프로세스 스케줄링, 파일 시스템 관리, 네트워킹 등의 기능을 제공합니다.
Docker는 리눅스 커널 의 기능을 활용하여 컨테이너를 격리하고 관리합니다. 이를 통해 여러 개의 컨테이너를 하나의 호스트 시스템에서 실행할 수 있으며, 각 컨테이너는 자신만의 파일 시스템과 프로세스 공간을 가집니다. 가상머신과 달리, Docker 컨테이너는 별도의 운영체제를 가지지 않아 가상 머신에 비해 좀 더 경량화 되었다고 할 수 있습니다.
네임스페이스란 리눅스 커널에서 프로세스 간에 격리된 환경을 제공하기 위한 핵심 기술 중 하나 입니다. 각 네임스페이스는 프로세스 그룹을 격리하고 관리합니다.
프로세스 그룹은 프로세스들의 논리적인 집합 입니다. 예를 들어, shell 에서 여러 명령어를 병렬 실행할 때, 각 명령어가 개별적인 프로세스 그룹으로 생성 되는 것과 같습니다. 각 프로세스 그룹에는 독립적인 환경이 제공 되며, 시스템에 대해 독립적인 접근 권한을 갖게 됩니다.
Shell (root)
│
├─ 프로세스 그룹 1 (네임스페이스)
│ ├─ 프로세스 A
│ └─ 프로세스 B
│
└─ 프로세스 그룹 2 (네임스페이스)
├─ 프로세스 C
└─ 프로세스 D리눅스에서 프로세스는 트리 구조를 가지며, 자식 프로세스는 부모 프로세스로부터 환경을 물려 받습니다.
아래 구조도는 하나의 호스트 시스템에서 두 개의 컨테이너가 있는 구조 예시 입니다. 각 컨테이너는 독립적인 네임스페이스를 가지고 있으며, 이 네임스페이스는 서로 독립적인 환경을 제공합니다.
호스트 시스템
│
├─ 컨테이너 1 (네임스페이스)
│ ├─ 프로세스
│ ├─ ...
│ └─ 프로세스
│
└─ 컨테이너 2 (네임스페이스)
├─ 프로세스
├─ ...
└─ 프로세스컨테이너 내에서는 여러 프로세스가 동작하며, 이러한 프로세스들은 해당 컨테이너의 네임스페이스 내에서 관리 됩니다. 이러한 구조를 통해 각 컨테이너는 자체적인 환경을 갖고 실행 되며, 서로 간에 영향을 미치지 않게 되는 것입니다.
cgroup
컨트롤 그룹(control group, cgroup)은 리눅스 커널의 기능 중 하나로, 각 프로세스 그룹의 시스템 자원을 관리하고 모니터링 하는 데 사용됩니다. Docker 컨테이너 기술 에서는, cgroup 을 이용하여 컨테이너 내의 프로세스 자원 사용량을 제한하고 관리합니다.
cgroup 역시 프로세스와 마찬가지로 계층적 트리 구조를 가지며, 부모의 정보를 상속 받아 사용할 수 있습니다.
이러한 cgroup은 네임스페이스와 연동하여 컨테이너 기술을 뒷받침 합니다.
컨테이너가 시작될 때, 새로운 네임스페이스가 생성 됩니다. 이 때, 동시에 해당 컨테이너의 프로세스들을 관리하기 위한 cgroup 도 생성 되게 됩니다.
네임스페이스는 컨테이너 내부 프로세스의 독립적인 접근 권한 을 제공하는 반면, cgroup 은 이러한 프로세스들이 사용하는 리소스를 제한하거나 관리하고, 모니터링 하게 됩니다. cgroup은 리눅스에서 멀티테넌시를 지원하는 데 중요한 역할을 합니다.
위에 설명한 네임스페이스와 cgroup 이외에도, 흥미롭고, 다양한 기술들이 Docker 와 함께 사용되며, 컨테이너 기술의 핵심을 이루고 있습니다. 내가 사용하는 도구가 어떤 기술로 구성 되어 있고, 어떻게 동작하는 지 이해함으로써, 업무의 효율성을 극대화 할 수 있었던 것 같습니다.
컨테이너 기술을 도입하면서, 필연적으로 고민 할 수 밖에 없었던 사항은 바로 ‘컨테이너 관리’ 입니다. 아직 프로젝트의 컨테이너화 작업 외에, 해결하지 못한 인프라 운영 과업이 많이 남아 있었습니다.
API 서버는 오토 스케일링이 적용 되어 있지 않아, 항상 최대 트래픽을 허용할 수 있을만큼의 리소스를 사용하고 있어야 했습니다. 이는 저희 규모의 스타트업에서 비용 낭비로 이어집니다. 스케줄러 역시, 작업 시각이 도래하지 않았음에도 인스턴스가 항상 띄워져 있어야 했습니다.
KT 클라우드는 AWS에 비해 기능이 한참이나 부족했습니다. 인프라의 전반적인 것들을 점차 AWS로 이전해야 했습니다. 또한, 불편한 로그 시스템과 운영에 필요한 인프라 매트릭 정보 수집이 부족했습니다.
위와 같은 문제들로 인해 AWS로의 이전과 AWS-EKS(Kubernetes) 도입을 결정하게 되었습니다.