아래 내용은 팀에 기술 공유 목적으로 작성 되었던 내용 입니다.
AWS-EKS(k8s) 환경에 Helm-Chart 를 이용하여, Sentry self-hosted 구축했던 경험을 담고 있습니다.
작업 했던 내용은 Github 링크에서 확인할 수 있습니다.
링크: https://github.com/Choi-Seunghwan/infra/tree/main/helm-sentry-hosted
배경과 목적
서비스에서 버그가 발생하면, CS로 상세한 리포트를 남겨주는 사용자는 사실 ‘고마운’ 사용자.
하지만 대부분의 사용자는 다음과 같은 흐름으로 움직임
- 서비스 버그 경험 → 신뢰도 하락 → 이탈
그리고 가장 무서운 버그는, 개발/QA 를 거쳐 배포된 기능이 유저 환경에서 ‘조용히’ 에러를 내고 있는 상황인데 우리는 모르고 있는 것
특히 클라이언트 애플리케이션은 구조적으로 에러 관측이 어려움.
- 유저 기기에서 실행되는 코드 특성상, 클라이언트 로그는 사실상 blind spot
- 클라이언트 환경의 다양성 : PC/모바일/태블릿 + Chrome/Safari 등 (GoodBye IE…)
- CS 가 들어오면 기기/버전/재현 경로를 물어야 하는데, 이 과정이 고객에게도 팀에게도 ‘취조’ 같은 경험이 될 수 있음
PoC 목표
위와 같은 상황을 해결하고자 이번 PoC 목표를 다음과 같이 수립함
- 클라이언트에서 발생하는 에러를 자동으로 수집
- 재현이 어려운 문제도 ‘어떤 환경에서 / 어떤 흐름에서 / 얼마나 자주’ 발생하는지 확인
- 빠르게 탐지하고, 빠르게 원인에 도달하기
- 우리가 모르는 ‘조용한’ 에러를 탐지하기
- 개인적으론, 백엔드 개발자로서 모니터링 시스템을 구축하며 백엔드/인프라 역량 강화
이를 위해, 에러 수집/모니터링 도구 중 하나인 Sentry 도입 기술 조사를 함
Sentry 소개
Sentry 는 클라이언트에서 발생하는 에러를 수집하고, 이를 개발자가 디버깅 가능한 형태로 정리해 주는 에러 추적 도구임.
- 어떤 코드 경로에서 에러가 발생 했는지 (stack trace)
- 어떤 환경에서 발생했는지 (브라우저, OS, 디바이스, 앱 버전 등)
- 어떤 사용자 흐름에서 발생했는지 (breadcrumb , context)
- 같은 유형의 에러가 얼마나 자주 발생 하는지 (그룹핑)
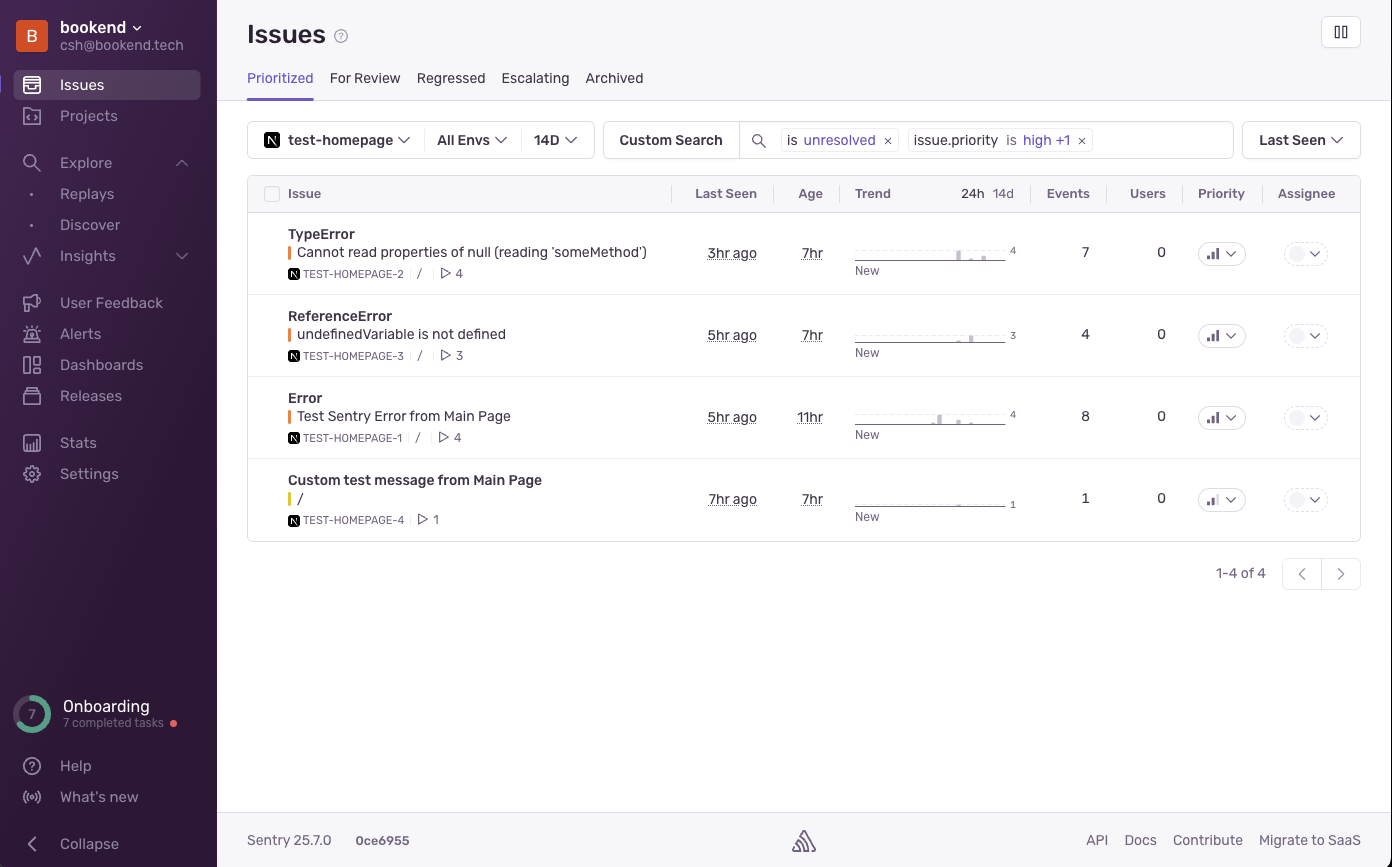
Sentry 대시보드.
Jira 에서 티켓으로 작업을 관리하듯, Sentry 에서 Issue 단위로 에러 관리 가능 (담당자 지정, 릴리즈 버전 등)
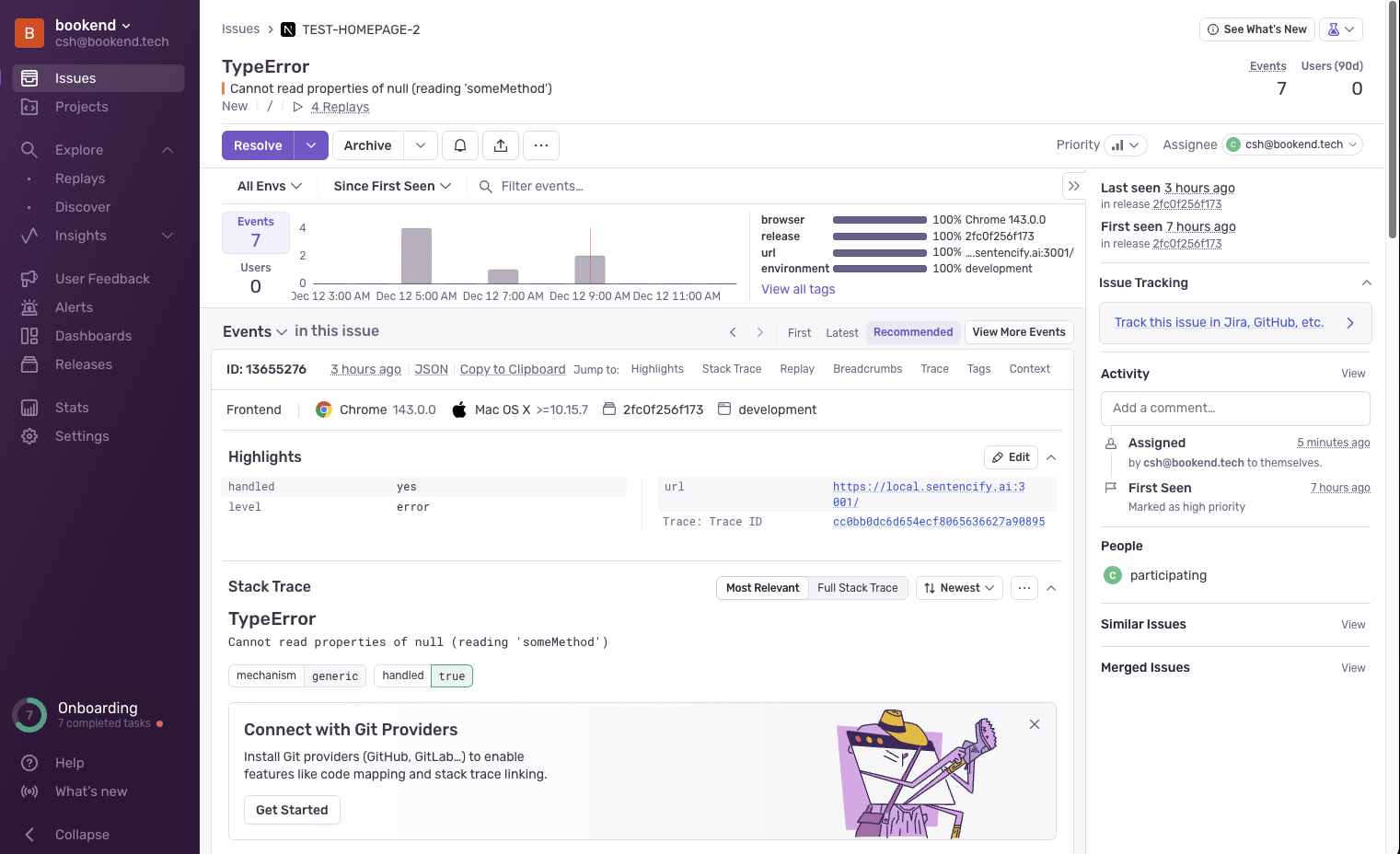
이슈 상세. 에러 발생 빈도, 발생 유저 등 요약 정보
홈페이지에 테스트용 버그 발생 버튼 생성
화면 기록 2025-12-12 오후 11.28.50.mov
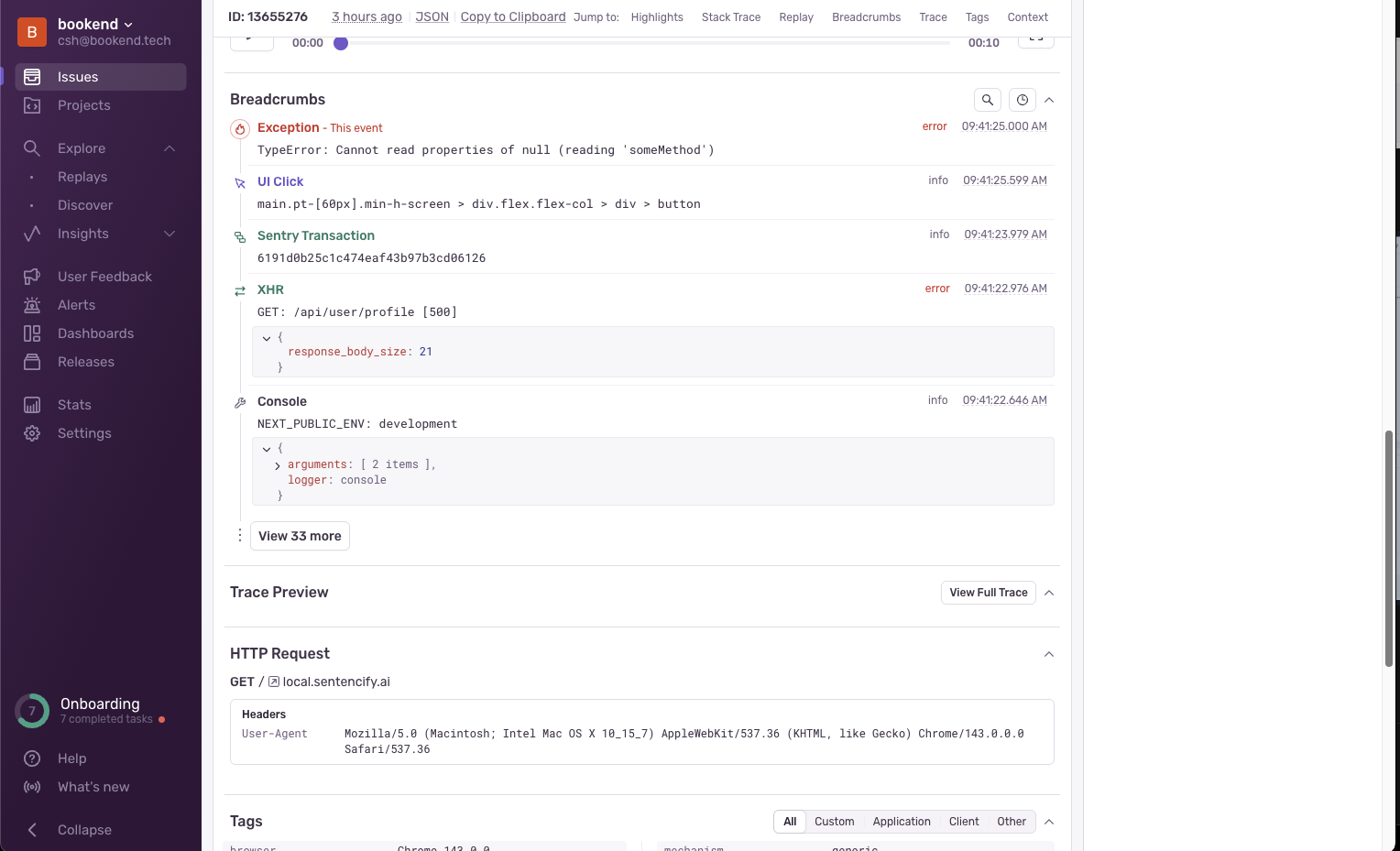
Session Replay. 에러 발생 시점의 유저 여정 영상. 문자열 마스킹 처리.
도입 전략
Sentry 를 도입하기 위한 방법으론 두가지가 있음
- Sentry SaaS : 클라우드 사용. (구독 비용 지불)
- Self-Hosted : 오픈소스 기반으로 직접 설치/운영
이번 PoC 에서는 self-hosted 방식을 적용해 보기로 함. 이유는 아래와 같음.
- SaaS 플랜에 따른 기능 제약, 사용량 한도, 보관 기간 등의 제약이 존재함
- 개발자 플랜(무료)가 있으나, 월 5k 에러 이벤트 제한으로 매우 제한적
- 팀 플랜(월 $26)은 가격은 합리적이며 월 50k 이벤트 한도 제한. Replay 50건 제한. 특히 프론트/앱은 유저 환경 다양성 때문에 에러 이벤트가 생각보다 빠르게 쌓일 가능성이 있음 (이전의 경험 상, 브라우저 렌더링 등의 이유로 에러 발생 코드가 반복 실행되는 경우가 있어, 에러 발생량이 급증했던 적이 있음)
- 비즈니스 플랜(월 $80). 소규모 팀에서 합리적인 가격은 아니게 보임. 각종 유료 플랜들은 우리 팀에서 아직 사용성 검증이 되지 않아 부담이 있었음
- 비용 최적화 가능성. 우리 팀은 이미 AWS EKS 를 사용하고 있고, ‘내부 모니터링 도구’ 는 웹서비스처럼 실시간성이 절대적인 시스템이라기보다는 운영 효율을 높이기 위한 지원 시스템이라고 판단했음
- Spot 인스턴스 기반으로 리밸런싱/일시 중단 리스크를 감수하더라도, 팀 플랜(월 $26) 대비 더 낮은 비용으로 운영할 수 있지 않을까 하는 생각이 있었음
self-hosted 배포 경험 (EKS + Helm)
Spot 인스턴스는 시기/가용영역(zone)에 따라 가격이 변동됨. AWS의 인스턴스 수급 상황에 따라 Spot 가격이 조정됨.
PoC 시점에는 서울 리전 기준 2vCPU 급 Spot이 시간당 약 $0.03 확인 되었음. t3a.large / m6g.large 급 인스턴스를 월 $20 정도로 운영 가능하다고 판단 했음
생각보다 거대한 시스템
처음에는 helm chart로 배포 진행이 잘 되는 것처럼 보여 이상 없는 줄 알았으나,
데이터 마이그레이션 job들이 hook으로 수행되고 난 뒤 consumer 등 다수의 pod가 본격적으로 뜨는 시점에 리소스가 급격히 치솟으며 워커 노드가 버티지 못하는 상황 발생함
Sentry 시스템의 구성 요소는 이와 같음.
- 데이터 파이프라인 및 저장소 : snuba, clickhouse, kafka, rabbitmq, postgresql 등
- 애플리케이션 및 Job : web, worker, consumer, cron 등
- 그 외, ingress/nginx 및 내부 설정, 초기화 job 등
즉 Sentry self-hosted 는 ‘에러 모니터링 도구 하나’ 라기보다, ‘분산 시스템’에 가까운 구조임을 체감함
리소스 최소화 시도
Self-Hosted 공식 문서에는 최소 권장 사양으로 4코어, 16GB RAM 으로 명시 되어 있음
PoC 초반에는 비용을 아끼기 위해 t3a.large 인스턴스 하나로 시작 하였는데, Helm install 및 마이그레이션 job 과정에서 리소스 부족 문제가 발생함
이에, 워커노드를 2대로 늘려 보았으나, 리소스 사용량이 큰 컴포넌트들이 특정 노드에 ‘쏠림 현상’ 이 발생하게 되면 job 수행 시점에 OOMKilled 가 발생함
설치 완료 후 운영 환경이라 상정 하더라도, 부하로 인한 노드 헬스체크 실패 → 노드 재스케줄링 → jobs 동작 → 다시 헬스 체크 실패 및 재스케줄링. 이러한 문제 상황이 발생할 수 있었음
그러나, 설치된 Pod 목록을 보면 billingMetricsConsumer , genericMetricsConsumer 등, 에러 모니터링과 관계 없어 보이는 Pod들이 배포되고 있는 것 같았음.
나는 Sentry 핵심 기능들을 사용하기 위해, profiles.feature-completed 옵션으로 배포하고 있었는데, 해당 옵션으로 설치하면 billing, metric 관련 불필요한 Consumer들이 함께 배포되는 구성이었음
따라서 아래와 같이 불필요한 Consumer 들을 비활성화 하여 리소스를 확보 하였음
# values.yaml
# Ingest consumers (필수 - 에러 추적)
ingestConsumerAttachments:
enabled: true
...
# Metrics consumers (비활성화 - 커스텀 메트릭 불필요)
billingMetricsConsumer:
enabled: false
genericMetricsConsumer:
enabled: false
metricsConsumer:
enabled: false
...
# 각종 요소들의 CPU,메모리 제한 리소스 설정
resources:
requests: { cpu: 50m, memory: 512Mi }
limits: { cpu: 200m, memory: 1Gi }이 부분이 매우 까다로웠는데, 어떤 것이 필수고 어떤 것이 불필요한 것인지 기술 조사 자체가 쉽지 않았고,
helm-chart 가 오픈소스로 운영되다 보니, 버전 별 values 구조 및 키 형식이 일관되지 않아, helm template 커맨드로 values 의 수정 사항이 제대로 반영 되었는지 검증하는 과정이 필요했음
Pod 이 지정된 워커 노드 그룹에 올라가지 않는 문제
Sentry 전용 노드 그룹으로 격리하기 위해 nodeSelector/tolerations 설정을 하였으나, 일부 컴포넌트 (Snuba consumer 등) 에서 설정이 전파되지 않는 문제가 발생
아래는 kyverno 정책 예시임
# values.yaml 일부
_nodeSelector: &sentryNodeSelector
eks.amazonaws.com/nodegroup: al2023-arm-sentry
_tolerations: &sentryTolerations
- key: dedicated
operator: Equal
value: sentry
effect: NoSchedule
...
global:
nodeSelector: *sentryNodeSelector
tolerations: *sentryTolerations
...
ingestConsumerAttachments:
enabled: true
nodeSelector: *sentryNodeSelector
tolerations: *sentryTolerations
...Sentry helm chart 가 구성 요소도 많고 복잡하다보니 global 설정, 직접 설정 하더라도 적용되지 않는 문제가 있었음
따라서 kyverno 를 도입하여, 특정 namespace(sentry)에 생성되는 pod에 대해 강제로 nodeSelector/tolerations 를 주입하는 방식으로 해결함
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
...
spec:
rules:
- name: inject-sentry-node-affinity
match:
any:
- resources:
kinds:
- Pod
namespaces:
- sentry
mutate:
patchStrategicMerge:
spec:
nodeSelector:
eks.amazonaws.com/nodegroup: al2023-arm-sentry
tolerations:
- key: dedicated
operator: Equal
value: sentry
effect: NoSchedule결과 m6g.xlarge 1대로 배포 성공
여러 차례의 리소스 조율, 노드 스케일업을 시도한 결과, 최종적으로 m6g.xlarge 1대 구성에서 안정적으로 전체 배포가 완료되었고, Spot 리밸런싱 과정에서도 15~20 분 정도 다운타임이 있지만, 재배포가 성공적으로 되었음
클라이언트단에서 적용 팁
NextJS, Electron, NuxtJS 등, Sentry 가이드가 잘 되어 있고, 요즘은 LLM 도움까지 받으면 SDK 부착 자체는 크게 어렵지 않음
다만, 단순히 기술을 ‘도입하는’ 것에서 끝내면 Sentry 와 같은 모니터링 도구는 금방 ‘노이즈 대시보드’가 되기 쉬움.
오히려 에러가 너무 많이 들어오면 무뎌짐. 레벨링/라벨링이 중요함
에러 이벤트가 과하게 쌓이면 Issue가 쌓여도 ‘늘 있는 에러’로 취급하고 주의깊게 해당 에러를 살펴보지 않게 됨 (점점 쌓임)
그래서 에러 중요도 레벨링이 필요함
type ErrorLevel = "error" | "warning" | "info" | "debug";
export function reportError(err: unknown, level: ErrorLevel = "error") {
Sentry.withScope((scope) => {
scope.setLevel(level);
if (err instanceof Error) {
Sentry.captureException(err);
} else {
Sentry.captureMessage(String(err));
}
});
}
...
try {
// ...
} catch (e) {
reportError(e, "error"); // 이와 같이 사용
}error: 기능 장애 (로그인, 결제 등 핵심 로직)warning: 부분 장애 / UI,UX 흐름에서 재시도 후 진입 가능info: 운영 관찰용 (정보, 추이 확인용)debug: 개발단에서 필요한 로그
에러가 아니어도 수집하기
클라이언트단에서 throw 를 발생하는 에러가 아님에도 장애급 상황이 발생할 수 있음. 예를 들어,
- 결제 관련 API 는 200으로 떨어질 수 있으나, 비즈니스적인 상태에서 에러일 수 있음
- UI가 깨지지만 프로그래밍적 예외는 발생하지 않음
// 개발자가 예상 가능한 로직 흐름 부분에서
if (paymentResult.status === "FAILED") { // 그 외 조건 추가
reportError(`Payment failed: ${paymentResult.reason}`, "warning");
}전역에서 에러 관리하기
Sentry 는 초기화 이후, uncaught exception 같은 핸들링 되지 않은 전역 에러를 자동 수집함
그리고 beforeSend 같은 코드 부분에서 노이즈를 걸러주면 대시보드 품질이 유지됨
import * as Sentry from "@sentry/browser";
Sentry.init({
dsn: process.env.NEXT_PUBLIC_SENTRY_DSN,
environment: process.env.NODE_ENV, // DEV | STAGE | PROD
// 과도한 에러로 인한 노이즈를 줄이는 코드 작성
beforeSend(event) {
const msg = event.message ?? "";
// 잘 알려진 프론트 노이즈 메세지 필터링
if (msg.includes("ResizeObserver loop limit exceeded")) return null;
// 그 외 불필요한 메세지 필터링
return event;
},
});후기
- 사실 본격적으로 PoC 해봐야지 하고 시작했던 작업은 아니라, 중간 과정들을 세세히 기록하지 못해 공유하면 좋았을 내용들이 일부 누락된 것 같습니다.
- SaaS 보다 저렴하게, 비용 효율적으로 구성할 수 있겠다! 라는 자신감으로 시작했으나… 결과론적으로 SaaS 의 가성비는 쉽게 이기기 어려웠습니다. 😂
- 현재는 https://sentry.sentencify.ai/ 주소에 배포되어 있습니다. 대시보드에서 프로젝트 추가 후, 간단하게 DSN 만 설정하면 사내 어느 프로젝트에서나 바로 사용 가능합니다.
- 물론 SaaS로 ‘딸깍’ 했으면 훨씬 빨리 끝났겠지만, 직접 구성하면서 배운 점이 많았습니다. 🫠
- 현재는 m6g.xlarge spot 노드에 배포되어 있으며, 기존 EKS 운영 비용을 제외하고, 노드+EBS 비용으로는 대략 $43로 예상하고 있습니다.
- 초기에 ‘적은 비용’ , ‘최소한의 리소스’를 목표로 하다보니 더 삽질하는 구간이 있었습니다. 그 과정에서도 알게된 게 많았습니다.
- …왠지 고양이 박사님 짤이 떠오르는군요. https://namu.wiki/w/니트로 박사